
![]()
Many modern Natural Language Processing tasks are cast as supervised classification problems. Machine Learning models such as deep neural networks learn from data, which in the case of NLP are documents or sentences in nautral language. The datasets used for training, however, contain several kinds of biases, including topic bias, usually introduced by the data collection procedures, e.g., keyword-based. Such biases have a negative effect on the capability of the model to effectively learn the target phenomen independently from the topic. We propose a method for alleviating this issue based on standard topic modeling paired with techniques borrowed from the machine learning fairness field. We train a model to learn a phenomenon from annotated data, while at the same time learning an inverse correlation between the data and the topic.
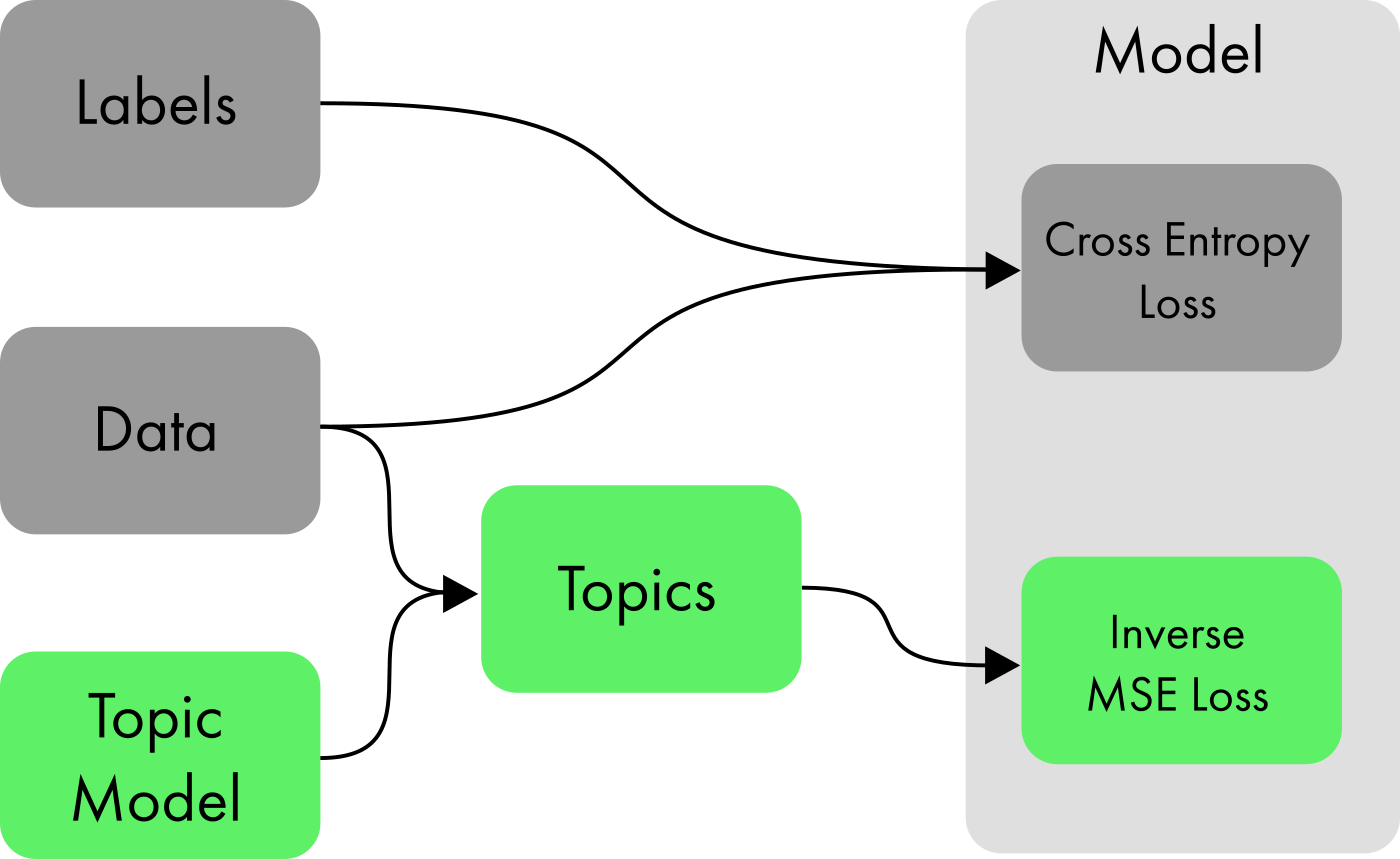
The method works by training a neural network with two outputs. One is the standard output node used for classification, with sigmoid activation, for binary classification or softmax for multiclass classification. The second output is a vector of nodes with a dimension matching the output of a topic model algorithm run on the same training data. The loss function for the network is a linear combination of two components:
- Cross-categorical entropy for the first output;
- The inverse of Minimum Squared Error for the second output;
A use case to exemplify why the topic bias problem is relevant is the automatic detection of abusive language. Wiegand et al. (2019) show how topic bias is problematic for this task, as supervised models learn patterns from the training data that are correlated with their topic. Using the trained model to predict abusive language in another dataset then yields sub-optimal results, even if the phenomenon (abusive language) is the same.